Chaire VISA DEEP
Towards visual reasoning in deep learning
Alexandre Ramé
Sorbonne Université
PhD Student. Thesis subject: deep ensembles to boost image understanding
Corentin Dancette
Sorbonne Université
PhD Student. Thesis subject: deep learning for vision reasoning




Objective
Our main objective is to tackle complex vision-driven recognition and understanding tasks. We propose to investigate tasks of visual reasoning beyond merely large scale image classification. It is required to decline some reasoning processes in the visual analysis scheme. We intend to explore the combination of elementary reasoning blocks into deep architectures. We want to question the type of blocks, structures and rules we can include. The main requirement in terms of types of structures we consider is to get a final hybrid (Explicit/Implicit) architecture that is end-to-end trainable. We already experimented in several contexts how performance increases using fully trainable architectures. Getting a differentiable function for the final DNN greatly constraints the type of combination or the nature of reasoning. We will consider different contexts including the VQA task to experiment our propositions. We also want to measure or visualize how the information is processed inside the deep nets. It is a key to our deep reasoning models being tooled up of explanation capacities. In particular, we will investigate different visualizing processes in the context of autonomous driving where building machines explaining their decisions is of critical importance.
Thematics
Multi-modal Learning and biases
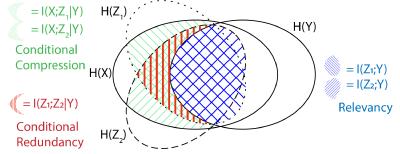
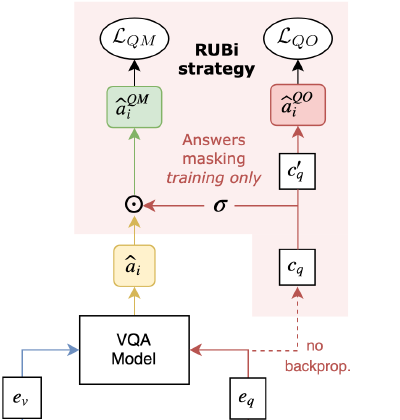
We aim at identifying and reducing biases when learning models, in particular for multimodal tasks such as Visual Question Answering (VQA). This task involves answering complex questions about images, and requires visual reasoning skills. Many biases have been highlighted on this task: models rely on superficial and spurious correlations (such as the sky is blue or a plane has two wings), often relying mostly on the text without considering the image. Thus, model fail to answer more complex cases.
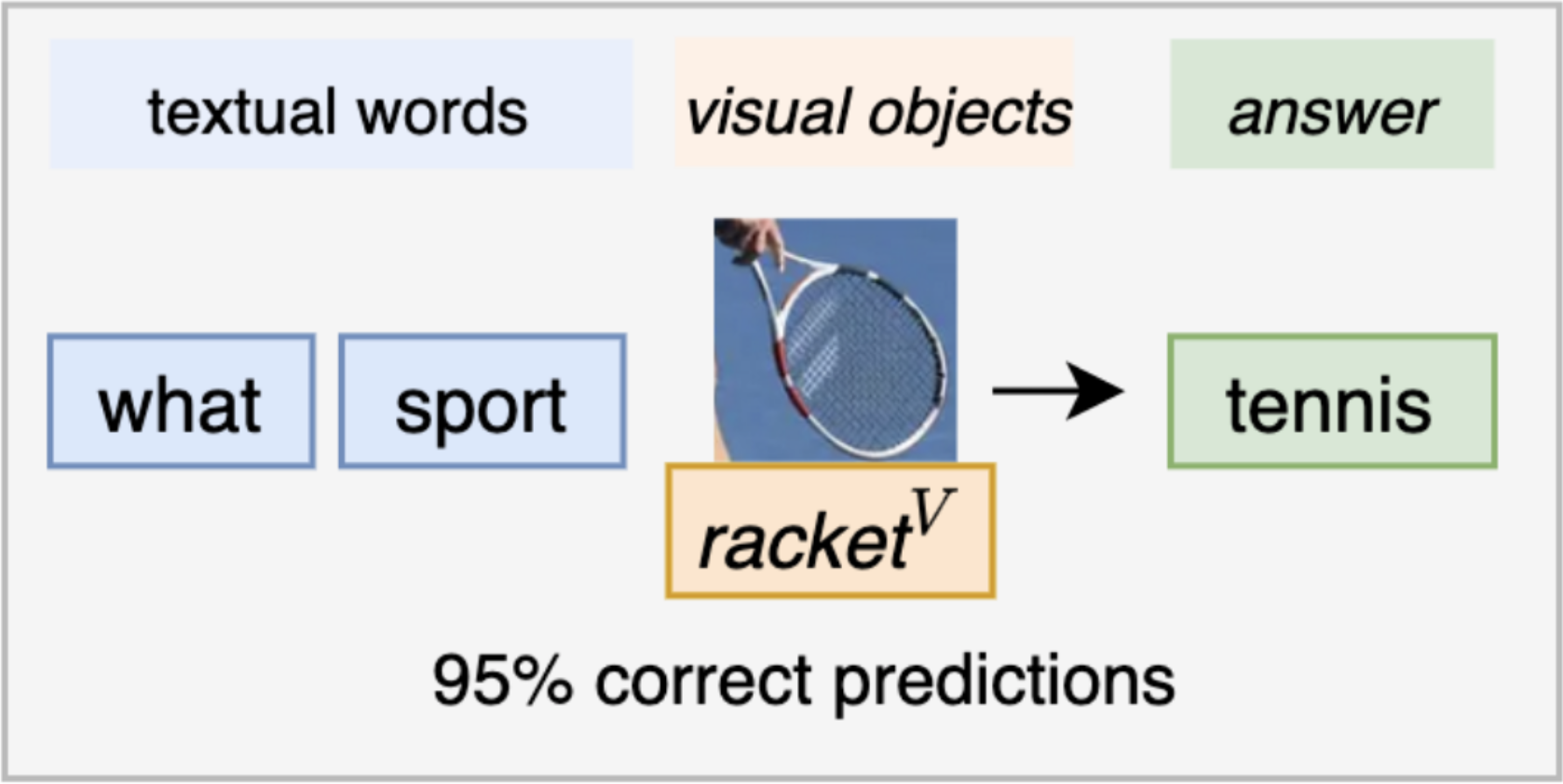
We propose methods to identify such shortcuts, and to reduce the learning of shortcuts in models.
Robustness of deep neural networks
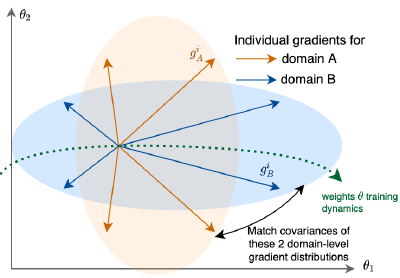
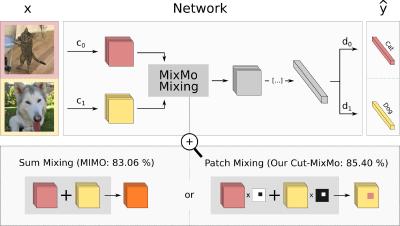
We aim at improving the robustness of deep learning networks, not despite the complexity of the models and data, but thanks to their diversity, respectively in predictions and in distribution. We study how the diversity across these models and datasets can enhance deep learning generalization abilities for classification in computer vision tasks. Analyzing these notions of diversity gives us the opportunity to better understand why deep learning work so well generally. To summarize our investigations: - We analyze deep ensembles, where multiple models are trained independently and then averaged to improve performances. - We consider setups in which multiple domains are given. When these domains contain the same classes, we propose new regularizations methods to promote the learning of a causal mechanism consistent across domains and improve ouf-of-distribution generalization.